Python Programming
Lecture 13 Web API and HTML Basics
13.1 Web API
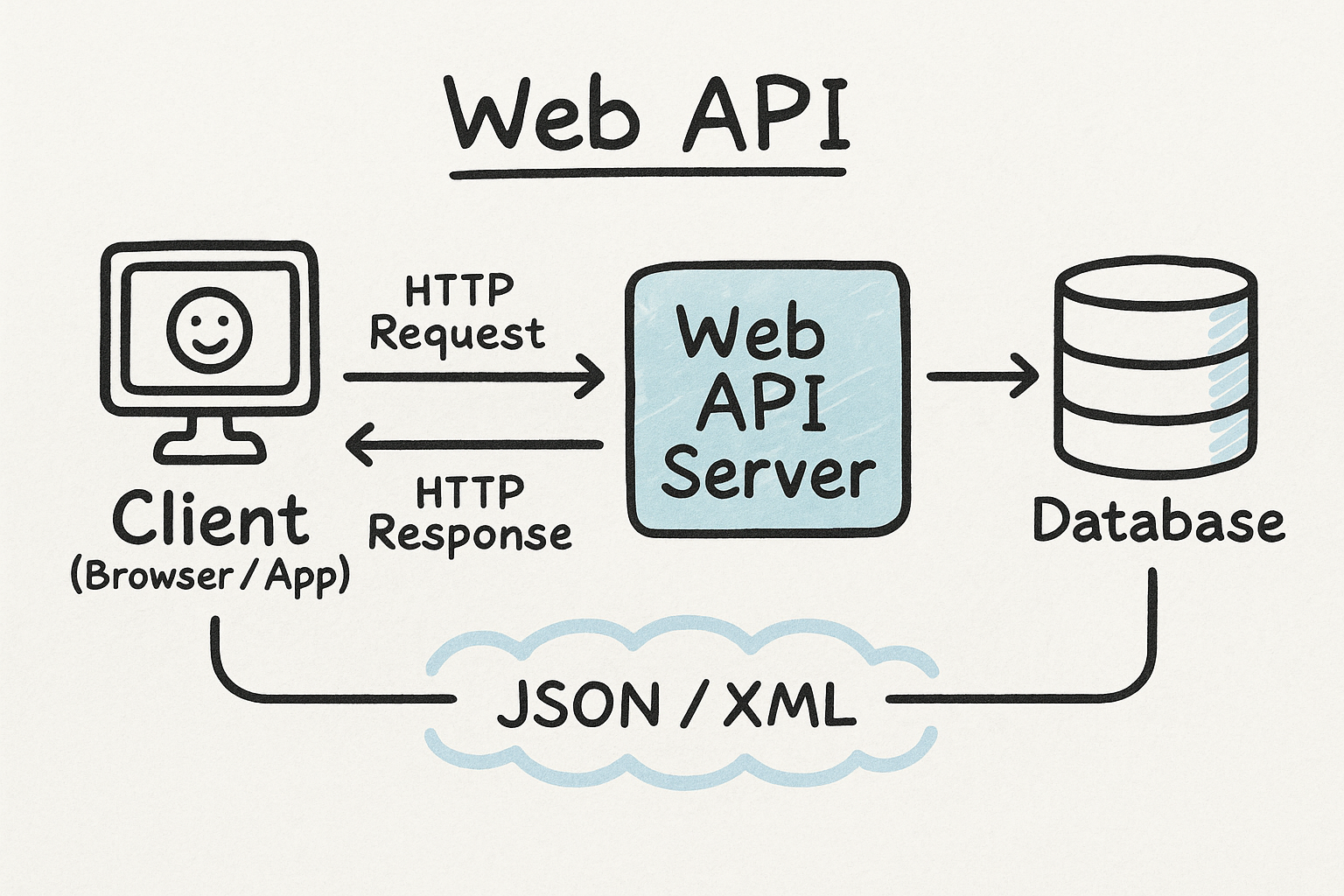
Weather Data
中国气象台大数据接口
import requests
url = "http://t.weather.itboy.net/api/weather/city/101020100"
r = requests.get(url)
print(r.status_code)
response_dict = r.json()
f = response_dict['data']
ff = f['forecast']
ff_today = ff[0]
ff_1 = ff[1]
ff_2 = ff[2]
def show(day):
for x in day:
print(x+': '+str(day[x]))
print()
show(ff_today)
show(ff_1)
show(ff_2)
Deepseek API开放平台
API说明文档
# Please install OpenAI SDK first: `pip3 install openai`
from openai import OpenAI
client = OpenAI(api_key="your api_key", base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "鲁迅暴打周树人"},
],
stream=False
)
print(response.choices[0].message.content)

GitHub 是一个基于 Git 版本控制系统 的 代码托管平台,由 GitHub 公司(现为 Microsoft 子公司)于 2008 年推出。它是全球最受欢迎的开源协作平台,广泛应用于软件开发、版本管理、团队协作和项目发布。GitHub官网地址:https://github.com, Github教程
Github的API接口(关于Python的项目)
https://api.github.com/search/repositories?q=language:python&sort=stars
import requests
url = 'https://api.github.com/search/\
repositories?q=language:python&sort=stars'
r = requests.get(url)
print("Status code:", r.status_code)
response_dict = r.json()
for keys in response_dict.keys():
print(keys)
Status code: 200
total_count
incomplete_results
items
- Working with the Response Dictionary
print("Total repositories:", response_dict['total_count'])
repo_dicts = response_dict['items']
print("Repositories returned:", len(repo_dicts))
Total repositories: 20566130
Repositories returned: 30
repo_dict = repo_dicts[0]
print("\nSelected information about first repository:")
print('Name:', repo_dict['name'])
print('Owner:', repo_dict['owner']['login'])
print('Stars:', repo_dict['stargazers_count'])
print('Repository:', repo_dict['html_url'])
print('Created:', repo_dict['created_at'])
print('Updated:', repo_dict['updated_at'])
print('Description:', repo_dict['description'])
Selected information about first repository:
Name: public-apis
Owner: public-apis
Stars: 339656
Repository: https://github.com/public-apis/public-apis
Created: 2016-03-20T23:49:42Z
Updated: 2025-05-16T06:51:23Z
Description: A collective list of free APIs
Where to find Web Api? Public APIs, 聚合数据, IMDB-API
TMDB-API, OMDB-API
import requests
api_access = 'Your API Key'
page = 1
url = f"https://api.tmdb.org/3/movie/\
top_rated?language=en-US&page={page}"
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_access}"
}
response = requests.get(url, headers=headers)
response_dict = response.json()
# print(response_dict)
movies=response_dict["results"]
print(len(movies))
for key, value in movies[0].items():
print(f"{key}: {value}")
adult: False
backdrop_path: /zfbjgQE1uSd9wiPTX4VzsLi0rGG.jpg
genre_ids: [18, 80]
id: 278
original_language: en
original_title: The Shawshank Redemption
overview: Imprisoned in the 1940s for the double murder of his wife and her lover,
upstanding banker Andy Dufresne begins a new life at the Shawshank prison,
where he puts his accounting skills to work for an amoral warden.
During his long stretch in prison, Dufresne comes to be admired by the other
inmates -- including an older prisoner named Red --
for his integrity and unquenchable sense of hope.
popularity: 115.576
poster_path: /9cqNxx0GxF0bflZmeSMuL5tnGzr.jpg
release_date: 1994-09-23
title: The Shawshank Redemption
video: False
vote_average: 8.705
vote_count: 26204
Downloading Images
poster = movies[0]['poster_path']
title = movies[0]['title']
img_url = f"https://image.tmdb.org/t/p/w500{poster}"
r = requests.get(img_url, headers=headers)
if r.status_code == 200:
with open(f'{title}.jpg', 'wb') as f:
f.write(r.content)
else:
print("download failed")
Top10
import requests
api_access = 'Your API Key'
page = 1
url = f"https://api.tmdb.org/3/movie/\
top_rated?language=en-US&page={page}"
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_access}"
}
response = requests.get(url, headers=headers)
response_dict = response.json()
movies=response_dict["results"]
top10 = movies[:10]
for movie in top10:
poster = movie['poster_path']
title = movie['title']
img_url = f"https://image.tmdb.org/t/p/w500{poster}"
r = requests.get(img_url, headers=headers)
if r.status_code == 200:
with open(f'{title}.jpg', 'wb') as f:
f.write(r.content)
else:
print("download failed")
Now Playing
import requests
api_access = 'Your API Key'
page = 1
url = f"https://api.tmdb.org/3/movie/\
now_playing?language=en-US&page={page}"
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_access}"
}
response = requests.get(url, headers=headers)
response_dict = response.json()
movies=response_dict["results"]
top10 = movies[:10]
for movie in top10:
poster = movie['poster_path']
title = movie['title']
img_url = f"https://image.tmdb.org/t/p/w500{poster}"
r = requests.get(img_url, headers=headers)
if r.status_code == 200:
with open(f'{title}.jpg', 'wb') as f:
f.write(r.content)
else:
print("download failed")
量化投资
Tushare, JoinQuant, AKshare
import akshare as ak
stock_zh_a_hist_df = ak.stock_zh_a_hist(symbol="600519", period="daily",\
start_date="20170301", end_date='20240528', adjust="")
print(stock_zh_a_hist_df)
- symbol为股票代码,adjust为是否复权
- 生成的格式为pandas包中的DataFrame格式
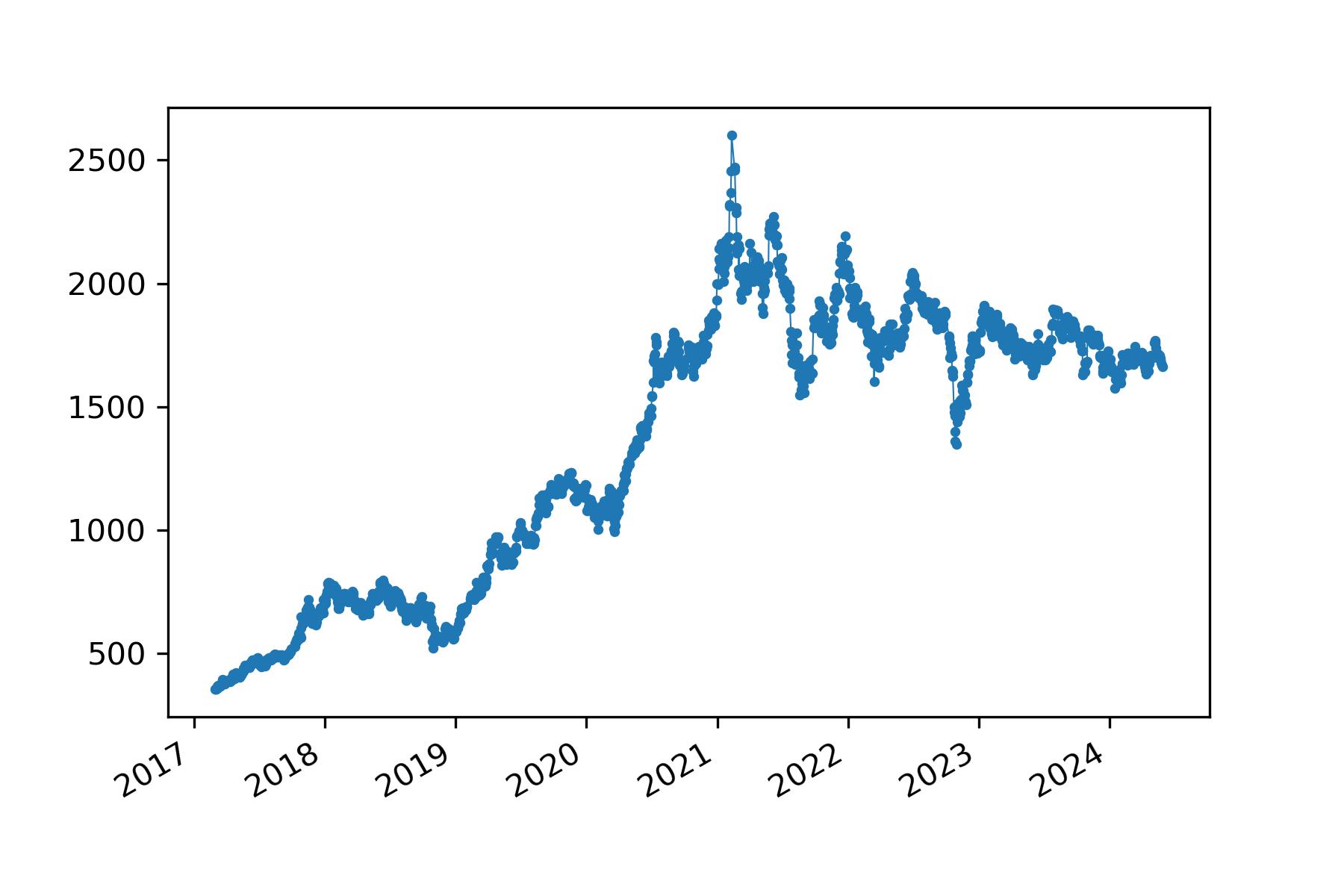
- “贵州茅台”收盘价绘图(2017-2024)
import matplotlib.pyplot as plt
from datetime import datetime
fig, ax = plt.subplots()
ax.plot(stock_zh_a_hist_df["日期"],stock_zh_a_hist_df["收盘"], linewidth=0.5)
ax.scatter(stock_zh_a_hist_df["日期"],stock_zh_a_hist_df["收盘"], s=5)
fig.autofmt_xdate()
plt.savefig('maotai.jpg',dpi=300)
Example: OMDB-API
import requests
import pandas as pd
# 电影名称
title = "Inception"
url = f"https://www.omdbapi.com/?t={title}&apikey=YOUR_API_KEY"
# 发起 GET 请求
response = requests.get(url)
data = response.json()
print(data)
# 选取想要的字段
movie_info = {
"Title": data.get("Title"),
"Year": data.get("Year"),
"Runtime": data.get("Runtime"),
"Genre": data.get("Genre"),
"Director": data.get("Director"),
"imdbRating": data.get("imdbRating"),
"Plot": data.get("Plot")
}
# 映射到 DataFrame(适合进一步分析)
df = pd.DataFrame([movie_info])
print(df)
13.2 HTML Basics
IP, DNS, URL, Hypertext (F12)

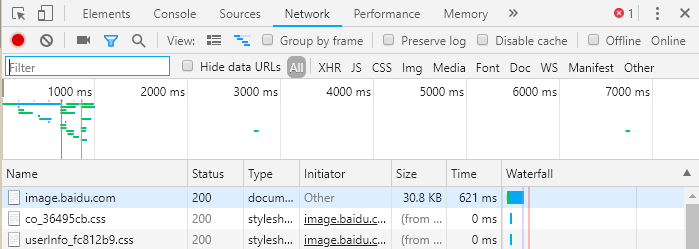
Requests: GET, POST
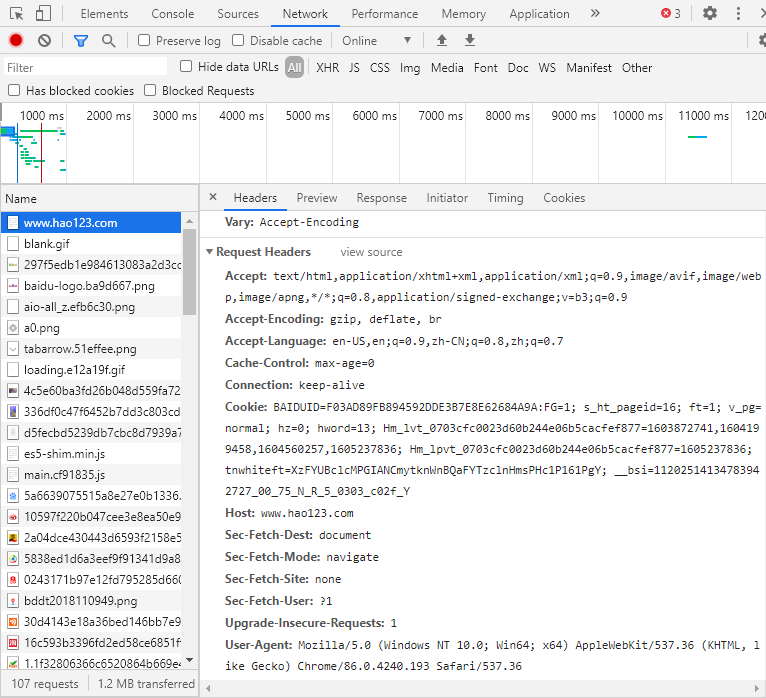
Response
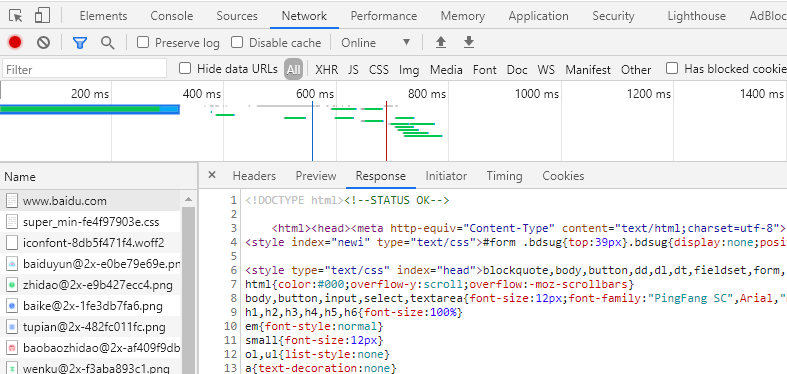
HTML, CSS, JavaScript
HTML DOM
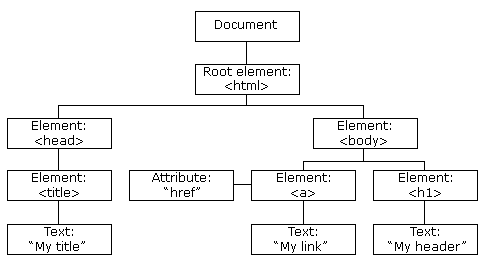
CSS Selector
id, class, tagname CSS Selector Reference
#container{
font-size: 50pt
}
.wrapper{
color: #a51f1f
}
div > p{
font-size: 20pt
}
爬虫
- 获取网页 (requests)
- 提取信息 (BeautifulSoup, Pyquery)
- 保存数据 (csv, xlsx, MySQL, MongoDB)
- JavaScript 渲染页面 (Selenium)
- 八爪鱼,火车头
其他相关概念
- 静态网页和动态网页
- Cookies, Session
- Proxy server
- 爬虫框架 (Scrapy)
Summary
- Reading: Python Crash Course, Chapter 16.2, 17