Python Programming
Lecture 17 Json, API and HTML Basics
17.1 Json and API
Write and Load
import json
numbers = [2, 3, 5, 7, 11, 13]
filename = 'numbers.json'
with open(filename, 'w') as f_obj:
json.dump(numbers, f_obj)
import json
filename = 'numbers.json'
with open(filename) as f_obj:
numbers = json.load(f_obj)
print(numbers)
JSON can't store every kind of Python value. It can contain values of only the following data types: strings, integers, floats, Booleans, lists, dictionaries, and NoneType. JSON cannot represent Python-specific objects, such as File objects, CSV Reader or Writer objects.
Web API
import requests
url = "http://t.weather.itboy.net/api/weather/city/101020100"
r = requests.get(url)
print(r.status_code)
response_dict = r.json()
f = response_dict['data']
ff = f['forecast']
ff_today = ff[0]
ff_1 = ff[1]
ff_2 = ff[2]
def show(day):
for x in day:
print(x+': '+str(day[x]))
print('\n')
show(ff_today)
show(ff_1)
show(ff_2)
Where to find Web API?
Public APIs, 聚合数据, 量化投研
Stock Market (股票市场)
url="http://img1.money.126.net/data/hs/kline/day/history/2020/1399001.json"
- 代码为股票代码,上海股票前加0,如600756变成0600756,深圳股票前加1
- 大盘指数数据查询:上证指数000001前加0,沪深300指数000300股票前加0,深证成指399001前加1,中小板指399005前加1,创业板指399006前加1
- 是否复权,不复权为kline,复权为klinederc
url="http://img1.money.126.net/data/hs/kline/day/history/2020/1399001.json"
贵州茅台
url="http://img1.money.126.net/data/hs/kline/day/history/2020/0600519.json"
import requests
import matplotlib.pyplot as plt
import pandas as pd
r = requests.get(url)
print(r.status_code)
response_dict = r.json()
# print(response_dict)
data = response_dict['data']
for x in data[:5]:
print("""日期: {},开盘价:{},收盘价:{},最高价:{}
最低价:{},交易量:{},涨幅跌幅:{}""".format(x[0],\
x[1], x[2], x[3], x[4], x[5], x[6]))
200
日期: 20200102,开盘价:1128.0,收盘价:1130.0,最高价:1145.06
最低价:1116.0,交易量:14809916,涨幅跌幅:-4.48
日期: 20200103,开盘价:1117.0,收盘价:1078.56,最高价:1117.0
最低价:1076.9,交易量:13031878,涨幅跌幅:-4.55
日期: 20200106,开盘价:1070.86,收盘价:1077.99,最高价:1092.9
最低价:1067.3,交易量:6341478,涨幅跌幅:-0.05
日期: 20200107,开盘价:1077.5,收盘价:1094.53,最高价:1099.0
最低价:1076.4,交易量:4785359,涨幅跌幅:1.53
日期: 20200108,开盘价:1085.05,收盘价:1088.14,最高价:1095.5
最低价:1082.58,交易量:2500825,涨幅跌幅:-0.58
import requests
api_access = 'Your API Key'
page = 1
url = f"https://api.themoviedb.org/3/movie/\
top_rated?language=en-US&page={page}"
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_access}"
}
response = requests.get(url, headers=headers)
response_dict = response.json()
# print(response_dict)
movies=response_dict["results"]
print(movies[0])
for key, value in movies[0].items():
print(f"{key}: {value}")
adult: False
backdrop_path: /tmU7GeKVybMWFButWEGl2M4GeiP.jpg
genre_ids: [18, 80]
id: 238
original_language: en
original_title: The Godfather
overview: Spanning the years 1945 to 1955, a chronicle of the fictional
Italian-American Corleone crime family. When organized crime family
patriarch, Vito Corleone barely survives an attempt on his life, his
youngest son, Michael steps in to take care of the would-be killers,
launching a campaign of bloody revenge.
popularity: 104.261
poster_path: /3bhkrj58Vtu7enYsRolD1fZdja1.jpg
release_date: 1972-03-14
title: The Godfather
video: False
vote_average: 8.7
vote_count: 17922
Downloading Images
poster = movies[0]['poster_path']
img_url = f"https://image.tmdb.org/t/p/w500{poster}"
r = requests.get(img_url, headers=headers)
if r.status_code == 200:
with open('The Godfather.jpg', 'wb') as f:
f.write(r.content)
else:
print("download failed")
Top10
import requests
api_access = 'Your API Key'
page = 1
url = f"https://api.themoviedb.org/3/movie/\
top_rated?language=en-US&page={page}"
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_access}"
}
response = requests.get(url, headers=headers)
response_dict = response.json()
movies=response_dict["results"]
top10 = movies[:10]
for movie in top10:
poster = movie['poster_path']
title = movie['title']
img_url = f"https://image.tmdb.org/t/p/w500{poster}"
r = requests.get(img_url, headers=headers)
if r.status_code == 200:
with open(f'{title}.jpg', 'wb') as f:
f.write(r.content)
else:
print("download failed")
Now Playing
import requests
api_access = 'Your API Key'
page = 1
url = f"https://api.themoviedb.org/3/movie/\
now_playing?language=en-US&page={page}"
headers = {
"accept": "application/json",
"Authorization": f"Bearer {api_access}"
}
response = requests.get(url, headers=headers)
response_dict = response.json()
movies=response_dict["results"]
top10 = movies[:10]
for movie in top10:
poster = movie['poster_path']
title = movie['title']
img_url = f"https://image.tmdb.org/t/p/w500{poster}"
r = requests.get(img_url, headers=headers)
if r.status_code == 200:
with open(f'{title}.jpg', 'wb') as f:
f.write(r.content)
else:
print("download failed")
17.2 HTML Basics
IP, DNS, URL, Hypertext (F12)

Requests: GET, POST
Response
HTML, CSS, JavaScript
HTML DOM
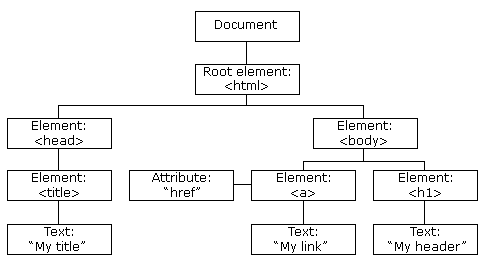
CSS Selector
id, class, tagname CSS Selector Reference
#container{
font-size: 50pt
}
.wrapper{
color: #a51f1f
}
div > p{
font-size: 20pt
}
爬虫
- 获取网页 (requests)
- 提取信息 (BeautifulSoup, Pyquery)
- 保存数据 (csv, xlsx, MySQL, MongoDB)
- JavaScript 渲染页面 (Selenium)
- 八爪鱼,火车头
其他相关概念
- 静态网页和动态网页
- Ajax渲染
- Cookies, Session
- Proxy server
- 分布式爬虫 (Scrapy)
Summary
- Reading: Python Crash Course, Chapter 16.2, 17